Haseung Jun
Samantha Himegarner
AP Biology 🧬
358 resourcesSee Units
Replication is the process in which genetic information is passed on to the next generation. In eukaryotes, this process takes place in the nucleus of the cell. Because prokaryotes do not have a nucleus, this process occurs in the cytoplasm. This is a multi-step process that employs the help of multiple enzymes.
🧬 DNA Replication
The DNA is twisted by nature, so the first step is to unwind and break the hydrogen bonds. A protein called helicase unwinds the DNA strands and breaks the hydrogen bond between each of the bases. But you know how twisted things behave when they are untwisted. They tend to twist back right? So protein called topoisomerase and single-strand binding proteins comes to the scene and relaxes the coil in front of the replication fork and prevents it from recoiling. Then comes the actual replicating part.
The DNA polymerase III has the main job of going through the template strand and adding the corresponding nucleotides. But here's the problem: the DNA polymerase III is a little timid, so it can't start anything on its own. This is when the RNA primase comes into play. The RNA primase is a protein and it adds something called a RNA primer, which is a short strand of RNA nucleotides. The DNA polymerase III only starts replication after the RNA primer is added.
Once it's done adding the corresponding nucleotides, the DNA polymerase I comes into play. Not only is the DNA polymerase III timid, it also makes a lot of mistakes. So it always needs a second pair of eyes to look over its work. The DNA polymerase I goes through the DNA replicated by DNA polymerase III and fixes any mistakes. It also goes through the RNA primer and changes it out with appropriate DNA nucleotides. Lastly, the ligase comes over and glues the newly replicated segment that used to be the RNA primer with the rest of the DNA strand. Here's a short list of what each protein does in an analogy.
Players of DNA replications:
- helicase - scissors
- topoisomerase and single-strand binding protein - relaxers
- DNA polymerase III - copier
- RNA primase - initiator (with RNA primer)
- DNA polymerase I - editor
- ligase - glue
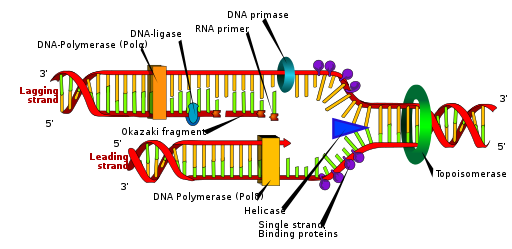
Image courtesy of WikiMedia Commons.
The Leading and Lagging Strand
But then we're hit with a huge problem. Replication is a “semiconservative” process, meaning it conserves one strand of DNA, unchanged, to serve as a template to create another. The DNA is processed in the 5’ → 3’ direction, or what is called the leading strand. DNA polymerase III can only work in the 5' → 3' direction. That's a problem because the other side of the DNA is in the 3'→5' direction, called the lagging strand. This is a huge problem right? 😱
Well this problem is semi-solved. Instead of simply working in one direction, DNA polymerase III works in the 5' → 3' direction from A to B, for example. Then, it moves to a new location, C, and works in the 5' → 3' direction again up A, which is where it started last time. Then, the DNA is unwound more, and DNA polymerase III works on another segment. These small segments are called Okazaki fragments. Once these fragments are made, ligase goes around and glues all the fragments together. Instead of a simple one-way replication, the lagging strand is a little more complicated, but in the end, two copies of DNA are made!
Side Notes
Unfortunately, as much as we would love for our body to be perfect in replicating our DNA, it's not. There are a few bases that are not replicated because the DNA polymerase III needs space to bind to the template strand (talk about inefficient proteins!). This means that every time our DNA is replicated, the chromosome loses a few base pairs. Our body tries to compensate for the loss by putting bits of unimportant DNA at the end, called telomeres. However, in the end, this doesn't really help, and our body ends up losing DNA. Unfortunately, when we lose all our DNA and end up only having telomeres, our body stop functioning 💀😭.
Conclusion
DNA replication is done through essentially unwinding DNA and then using the existing strand as a template. The proteins involved do their part in replicating. The helicase acts as "scissors" of the DNA and cuts the DNA by breaking hydrogen bonds between the nucleotides. The topoisomerase and single-strand binding proteins then keep the DNA from recoiling and messing things up. DNA polymerase III (highly inefficient, needs a lot of conditions satisfied before actually working) is the copier and adds the corresponding nucleotides. But remember! It can't start without a RNA primer, so the RNA primase has to go and add a primer consisting of RNA nucleotides. Then, DNA polymerase III can do its job. But since it makes a lot of mistakes, the DNA polymerase I goes back and edits any mistakes and replaces the RNA primer with actual DNA nucleotides. Lastly, the ligase is the glue!
Also remember that the DNA polymerase III only in the 5' → 3' direction, so the lagging strand is replicated through a series of Okazaki fragments. The leading strand is simply just replicated without much difficulty!
Try to explain this to a friend or yourself; explaining concepts out loud always proves to be the best study tip when trying to understand complicated processes.
Check out the AP Bio Unit 6 Replays or watch the 2021 Unit 6 Cram
Browse Study Guides By Unit
🧪Unit 1 – Chemistry of Life
🧬Unit 2 – Cell Structure & Function
🔋Unit 3 – Cellular Energetics
🦠Unit 4 – Cell Communication & Cell Cycle
👪Unit 5 – Heredity
👻Unit 6 – Gene Expression & Regulation
🦍Unit 7 – Natural Selection
🌲Unit 8 – Ecology
📚Study Tools
🧐Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.