1.3 Defining Psychological Science: The Experimental Method
5 min read•june 18, 2024
Sadiyya Holsey
Dalia Savy
AP Psychology 🧠
334 resourcesSee Units
Types of Research
Basic Research is performed to learn about something. It is curiosity-driven and used to expand upon knowledge. It doesn't have an immediate objective. An example of basic research would be a study assessing the impacts of caffeine ☕️ consumption on the brain. As you can see from the example, the goal is not to solve a problem it is only to increase knowledge about a particular topic.
Applied Research answers specific questions and is used to solve a problem or do something of practical use. An example of applied research would be trying to find a cure for obsessive-compulsive disorder.
The Scientific Method
Even though you have probably learned this a million times, here is a quick overview:
- First, the researcher would make a theory to try and explain the behavior that we are observing.
- This theory would then produce a hypothesis, or an educated guess/testable prediction.
- However, theories could bias our observations. Think about it: if you want to prove your theory correct, you would try and make it so the results prove it.
- To avoid this bias, psychologists use something called an operational definition.
- How do you test something if every researcher describes it in a different way, possibly, even, in a biased way?🤔
- Operational Definitions are statements of the exact procedures used in the study, which would eventually allow other researchers to replicate the research.
- Here's an example: how would you describe human intelligence?
- You may have said how smart someone is, measured by their grades, but this is a biased definition. The operational definition would be what an intelligence test (such as an IQ test) measures.
Types of Variables
There are several types of variables in an experiment. There is the independent variable, dependent variable, confounding variables, and control variables.
- The independent variable is the variable that changes in an experiment. For example, a researcher wanted to see how sleep affects performance on a certain exam. The researcher would change the amounts of sleep given to the subjects in order to see any changes.
- The dependent variable is the effect of the change in the experiment. This is what gets measured. For example, in the earlier example with sleep 😴 and performance on exams, sleep is the independent variable and the performance on the exam is the dependent variable, because performance on the exam “depends” on the independent variable, sleep.
- The confounding variable is an outside influence that changes the effect of the dependent and independent variables. For example, say there is a correlation between crime and the sale of ice cream🍨. As the crime rate increases, ice cream sales also increase. So, one might suggest that criminals cause people to buy ice cream or that purchasing ice cream causes people to commit crimes. However, both are extremely unlikely.
- The confounding variable includes a new outside variable not present in the original experiment. In our ice cream example, let's look at the weather, which could be the reason for the correlation. Ice cream is more often sold when it is hot outside, and people are more likely to commit crimes when it is hot outside because there is more social interaction. In the winter, people are less likely to buy ice cream, and there is also less social interaction. ☀️
- To recall from key topic 1.2, the Hawthorne Effect exists as well. If a researcher is observing people, those people would behave differently when they realize they are being watched, impacting the results of the naturalistic observation.
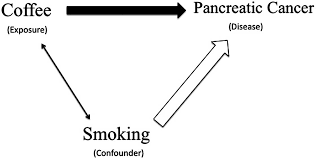
Image Courtesy of Kiana Matthews.
- The control variable is the variable that's kept the same throughout an experiment. For example, if a researcher wants to see how sleep affects performance on a test, the control variables could be the test, sleeping atmosphere, and the type of bed. These would all be kept the same throughout the research.
Why do we need a control variable?
Well, then you can prove why something happened without an alternate explanation. You can’t say the type of bed or the difficulty of the test impacted those results if the researcher kept those the same throughout the experiment.
Cause and Effect
Remember: Experiments are the only research that can determine cause and effect.
Also, a researcher must use random assignment to demonstrate cause and effect. Random assignment is when participants are assigned to each experimental group with an equal chance ⚖️ of being chosen. Don't confuse this with a random sample: each individual in the population has an equal chance of participating in an experiment.
Random assignment is randomly selecting people to be in an experimental group while random sample is randomly selecting people from the population to be in the experiment as a whole. Both random sampling and random assignment ultimately lead to the most accurate results.
Types of Bias
Sampling bias is a result of a flawed sampling process that produces an unrepresentative sample.
Experimenter bias is when researchers influence the results of an experiment to portray a certain outcome. A double-blind procedure is when neither the researcher or the participants know what groups the participants have been assigned to. This helps prevent bias when the researcher is looking over the results.
Common Sense?
Researchers and scientists cannot rely on common sense because of three main concepts:
- Hindsight Bias: the tendency to believe that you knew what was going to happen, as if you foresaw the event: "I knew it all along."
- Overconfidence: we are often overconfident in what we find/believe, which misleads others about the truth.
- We perceive order in events that are completely random. You can see this with coin flips. If you were to ask a group of students to flip a coin 50 times and record data, you'd be able to easily tell who actually did the assignment and who thought they could just make up the results. Those that actually did the assignment would have had long chains of heads or long chains of tails (HHHHHHH/TTTTTTT) while those that didn't would just alternate between the two (HTHTHTHHTTHTHT). We are generally unable to understand randomness since we always try to make sense of it.
Browse Study Guides By Unit
🔎Unit 1 – Scientific Foundations of Psychology
🧠Unit 2 – Biological Basis of Behavior
👀Unit 3 – Sensation & Perception
📚Unit 4 – Learning
🤔Unit 5 – Cognitive Psychology
👶🏽Unit 6 – Developmental Psychology
🤪Unit 7 – Motivation, Emotion, & Personality
🛋Unit 8 – Clinical Psychology
👫Unit 9 – Social Psychology
🗓️Previous Exam Prep
📚Study Tools
🤔Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.