3.5 Introduction to Experimental Design
8 min read•june 18, 2024
Kanya Shah
Jed Quiaoit
AP Statistics 📊
265 resourcesSee Units
This part focuses on the components in designing an experiment and how to increase the accuracy of the results. Understanding how to avoid bias from the previous sections above relates to experiments, especially when ensuring that the data collected is representative at a population level.
An experiment is a research method that is used to study the relationship between an independent variable (the treatment or intervention being imposed on individuals) and a dependent variable (the response or outcome being measured). In an experiment, the researcher intentionally imposes some treatment or intervention on a group of individuals (the experimental group) and compares their responses to a control group, which does not receive the treatment. 🔭
🗃 Components of an Experiment
In an experiment, the experimental units are the individuals or objects that are assigned treatments or interventions. These may be people, animals, cells, plants, or other objects of study. When the experimental units are people, they are often referred to as participants or subjects.
The response variables in an experiment are the outcomes that are measured after the treatments have been administered. The response variables are what the researcher is interested in studying and are used to determine the effects of the treatments.
The explanatory variables (also called factors) in an experiment are the variables whose levels are manipulated intentionally by the researcher. The levels or combination of levels of the explanatory variable(s) are called treatments. The explanatory variables are what the researcher is manipulating in order to study the effects on the response variables.
Example
Consider an experiment that is designed to study the effects of different types of exercise on weight loss. In this experiment, the explanatory variable would be the type of exercise (e.g., running, swimming, lifting weights), and the response variable would be the amount of weight loss. The experimental units would be the individuals who are assigned to different treatments (e.g., running, swimming, lifting weights) and who are measured for their weight loss after the treatments have been administered.
By manipulating the levels of the explanatory variable (the type of exercise) and measuring the response variable (the amount of weight loss), the researcher can study the relationship between the two variables and determine whether different types of exercise have different effects on weight loss.
Confounding
Sometimes, experiments don't run smoothly due to the nature of the set-up or the way the variables are considered.
For one, a confounding variable in an experiment is a variable that is related to the explanatory variable and influences the response variable, but is not being manipulated or controlled by the researcher. This means that the confounding variable may create a false perception of association between the explanatory variable and the response variable, making it difficult to determine the true effects of the explanatory variable.
For example, consider the same experiment designed to study the effects of different types of exercise on weight loss. If the experimental units are not controlled for factors such as age, diet, and genetics, these variables may act as confounding variables that influence the response variable (weight loss) and may create a false perception of association between the explanatory variable (type of exercise) and the response variable.
To control for confounding variables in an experiment, it is important to carefully design the study to minimize their influence and to use appropriate statistical methods to analyze the data. This may involve using random assignment to control for known confounding variables, using statistical models to adjust for confounding variables, or using matching or stratification techniques to ensure that the experimental groups are similar in terms of known confounding variables.
By controlling for confounding variables, researchers can more accurately determine the true effects of the explanatory variable on the response variable.
🖋 Elements of a Well-Designed Experiment
A well-designed experiment should include the following elements: ✔️
- Comparisons of at least two treatment groups, one of which could be a control group: In an experiment, it is important to compare the responses of the experimental units to at least two different levels or combinations of levels of the explanatory variable. This allows the researcher to determine the effects of the different treatments on the response variable and to identify any differences between the treatments.
One of the treatment groups may be a control group, which does not receive the treatment and serves as a baseline comparison for the other treatment groups.
- Random assignment/allocation of treatments to experimental units: To ensure that the results of the experiment are not biased, it is important to randomly assign the treatments to the experimental units. This means that each experimental unit has an equal chance of being assigned to any of the treatment groups, and that the treatment groups are similar in terms of known confounding variables.
Random assignment helps to control for these variables and ensures that the results of the experiment are not influenced by other factors.
- Replication (more than one experimental unit in each treatment group): It is important to include more than one experimental unit in each treatment group to ensure that the results are not due to chance or to the characteristics of a single unit.
This allows the researcher to calculate statistical measures such as the mean and standard deviation and to make more accurate and reliable conclusions about the effects of the treatments.
- Control of potential confounding variables where appropriate: To accurately determine the effects of the treatments on the response variable, it is important to control for potential confounding variables that may influence the results of the experiment.
This may involve using random assignment to control for known confounding variables, using statistical models to adjust for confounding variables, or using matching or stratification techniques to ensure that the experimental groups are similar in terms of known confounding variables. By controlling for confounding variables, researchers can more accurately determine the true effects of the explanatory variable on the response variable.
To design experiments properly, start with the most simple elements of an experiment which is the experimental units first, next the treatments, and finally measuring the responses.
- A control group is a collection of experimental units either not given a treatment of interest or given a treatment with an inactive substance (placebo) in order to determine if the treatment of interest has an effect. Control groups help deal with confounding because you remove the chance that an outside influence would affect the results.
- Random assignment to the experimental units is extremely important because you eliminate confounding and large differences between the treatment groups.
- Replication (repeatability) ensures the validity of your data because if you repeatedly get similar responses, that means your conclusion and analysis is accurate.
- Avoiding confounding is vital because if you need to establish causation but can’t identify the effects of the explanatory variables, the experiment data is useless.
A placebo is a treatment that has no active ingredient but is otherwise like the other treatments. Sometimes, it won’t make sense for there to be a placebo group. The placebo effect occurs when some subjects in an experiment responded favorably to any treatment, even an inactive one. 🤭
🗄 Types of Experiments
Blind Experiments
In a double blind experiment, neither the subjects nor those who interact with them and measure the response variable know which treatment a subject receives. This helps avoid confounding and personal bias towards a certain outcome. In a single blind experiment, the subjects don’t know which treatment they are receiving or the people who interact with them and measure the response variable don’t know which subjects are receiving the treatment. In this type, one or the other (subject or administrator) knows, not both. 🙈
Completely Randomized Design
In a completely randomized design, the experimental units are assigned to the treatments completely by chance. Assignment of treatment to the groups must be random. The group sizes won’t always be exactly even. This is the simplest statistical design for experiments but when there are clear distinctions or similarities within the chosen experimental units, that’s when you need a more specific experimental design. 🎰
Methods for randomly assigning treatments to experimental units in a completely randomized design include using a random number generator, a table of random values, drawing chips without replacement, and the like.
Randomized Block Design
In a randomized complete block design, treatments are assigned completely at random within each block. Blocking is a technique that is used to control for variables that may influence the response variable and that are not being manipulated in the experiment. By dividing the experimental units into blocks based on one or more blocking variables, researchers can ensure that the units within each block are similar to each other with respect to these variables. 🚫
For example, consider an experiment that is designed to study the effects of different types of fertilizers on plant growth. If the experimental units are plants, the blocking variable might be the soil type. The researcher could divide the plants into blocks based on soil type, and then assign the treatments (different types of fertilizers) randomly to the plants within each block. This would ensure that the plants within each block are similar in terms of soil type, which is known to influence plant growth.
The figure below shows an example of assigning treatments to block experiments in the context of students and exam results:
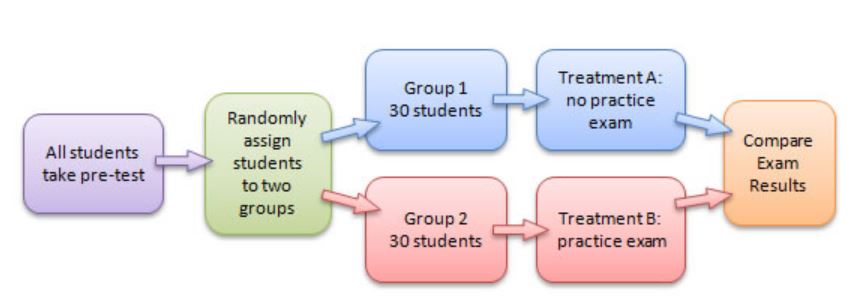
Image Courtesy of Elign Community College
Matched Pairs
A matched pairs design is a special case of a randomized block design, as it involves the use of a blocking variable (the matched pairs) to control for variables that may influence the response variable and that are not being manipulated in the experiment. 🥰
A matched pairs design works in which subjects (whether they are people or other objects of study) are arranged in pairs that are matched on relevant factors, such as age, gender, or other characteristics. The pairs may be formed naturally, or they may be created by the researcher.
In a matched pairs design, each pair receives both treatments in a random order, either by randomly assigning one treatment to one member of the pair and the other treatment to the second member of the pair, or by giving each subject both treatments. This allows the researcher to compare the responses of the subjects to the two treatments and to determine the effects of the treatments on the response variable.
It is possible to establish causation with experiments only because treatment is imposed. That’s a major difference between studies and experiments.
💡 Remember: Control what you can, block on what you can’t control, and randomize to create comparable groups. Be careful with combining study lingo with experiments!
🎥 Watch: AP Stats - Experiments and Observational Studies
Browse Study Guides By Unit
👆Unit 1 – Exploring One-Variable Data
✌️Unit 2 – Exploring Two-Variable Data
🔎Unit 3 – Collecting Data
🎲Unit 4 – Probability, Random Variables, & Probability Distributions
📊Unit 5 – Sampling Distributions
⚖️Unit 6 – Proportions
😼Unit 7 – Means
✳️Unit 8 – Chi-Squares
📈Unit 9 – Slopes
✏️Frequently Asked Questions
📚Study Tools
🤔Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.