5.4 Biased and Unbiased Point Estimates
5 min read•june 18, 2024
Jed Quiaoit
B
Brianna Bukowski
Josh Argo
AP Statistics 📊
265 resourcesSee Units
How to Tell if a Sample is Unbiased
An unbiased estimator is one that produces estimates that are on average as close as possible to the true population parameter. This means that if you repeatedly draw samples from the population and use the estimator to make inferences about the population parameter, the average of those estimates will be equal to the true population parameter. ⚖️
For example, if you wanted to estimate the mean height of all the students in your school, you could take a sample of students and measure their heights. If the mean height of the sample (the sample statistic) is equal to the mean height of the entire school (the population parameter), then your estimator is unbiased. On the other hand, if the sample mean consistently underestimates or overestimates the true mean height of the school, then your estimator is biased.
A sample is unbiased if the estimator value (sample statistic) is equal to the population parameter. For example, if the sampling distribution mean (x̅) is equal to the population mean (𝝁) or if the average of our sample proportions (p) is equal to our population proportion (𝝆), then our sample is unbiased! 😌
How to Tell if a Sample has Minimum Variability
A sampling distribution has a minimum amount of variability (spread) if all samples have statistics that are approximately equivalent to one another.
It is impossible to have no variability, due to the nature of random sampling. This is because the sample you are using to make the inference is only a small subset of the entire population, and so it is subject to sampling error. Therefore, there will always be some level of uncertainty or variability in the estimate when you use an estimator to make inferences about a population parameter.
However, a larger sample size will minimize variability in a sampling distribution! 🗽
Bias and Variability
A Recap on Skewness
Skewness is a measure of the symmetry of a distribution. A distribution is symmetric if it is roughly the same on both sides of the center, like a bell curve. A distribution is skewed if it is not symmetric, with more of the values clustered on one side or the other. For example, if a distribution is skewed to the left, it means that there are more values on the right side of the distribution and fewer values on the left side. 🔔
If a sample is equally spread out around the mean, it is not necessarily unbiased, but it is less likely to be biased than a sample that is heavily skewed in one direction or the other. However, other factors can also contribute to bias, such as sampling methods or the way that the sample was collected.
Bias relates to how skewed (also how screwed) the distribution is. Specifically, if an entire distribution is on the left side of our population parameter, it is skewed to the left. If a sample is equally spread out around the mean, then there is no bias.
The more spread out a distribution is, the more variability it has. The standard deviation of the sampling distribution is the estimator of the population standard deviation. If the standard deviation of the sampling distribution is equal to population standard deviation, it is said that the standard deviation of sampling distribution is the consistent estimator. High variability can be fixed by increasing your sample size, but if your sample does have high bias, there is no statistical way to fix it.
A good illustration for bias and variability is a bullseye. Bias measures how precise the archer is (how close to the bullseye), while variability measures how consistent he/she is. See the illustrations below for different circumstances regarding bias and variability: 🎯
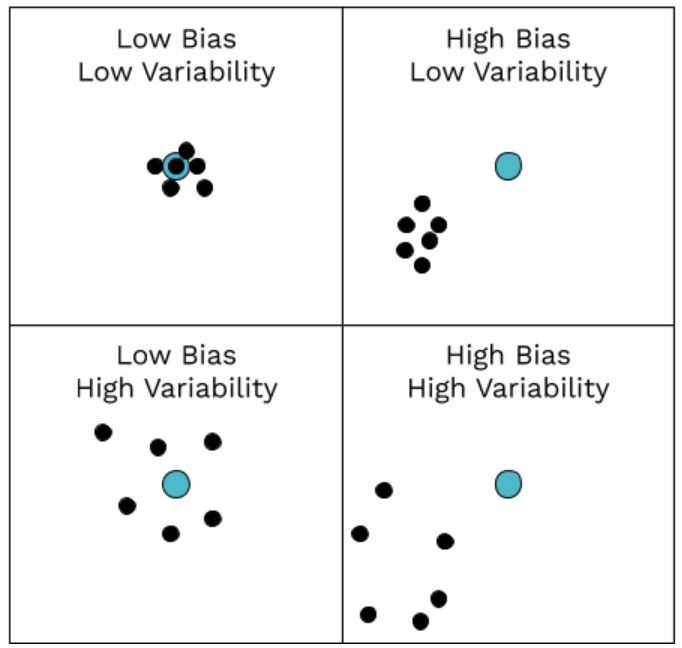
In this analogy, the bullseye represents the true population parameter, and the archer's shots represent the estimates produced by the estimator.
If the archer is very accurate but not very consistent, their shots will be close to the bullseye but may be scattered around it. This would correspond to a situation where the estimator has high variability but low bias.
On the other hand, if the archer is very consistent but not very accurate, their shots will all be close to each other but may be far from the bullseye. This would correspond to a situation where the estimator has high bias but low variability.
A good estimator should aim for both low bias and low variability, producing estimates that are both accurate and consistent.
Practice Problem
Suppose that you are asked to estimate the mean income of all the households in your town. You decide to use a sample of 100 households, selected using a random sampling method. After collecting the data, you calculate the sample mean income to be $50,000.
a) Explain whether or not this sample is biased, and give a reason for your answer.
b) Explain whether or not the sample mean income is an unbiased estimator of the population mean income, and give a reason for your answer.
c) Suppose that you later learn that the true population mean income is actually $55,000. Explain how this information affects your conclusions about the bias of the sample and the estimator in parts (a) and (b).
d) Discuss one potential source of bias that could have affected the results of this study, and explain how it could have influenced the estimate of the population mean income. (Note how this connects to Unit 3: Collecting Data)
Answer
a) Since the sample of 100 households was selected using a random sampling method (i.e., SRS, stratified or cluster sampling), the sample is not biased as it is representative of the entire population and its characteristics.
b) The sample mean income is an unbiased estimator of the population mean income if the sample was selected randomly and is representative of the entire population. If the sample meets these conditions, then the sample mean should be an unbiased estimate of the population mean, on average. Again, since we used a random sampling method, the sample mean income is indeed an unbiased estimator.
c) If the true population mean income is actually $55,000, this suggests that the sample mean income of $50,000 is an underestimate of the population mean. This means that the sample is biased, because it consistently produces estimates that are too low. It also suggests that the sample mean is a biased estimator, because it systematically produces estimates that are too low.
d) One potential source of bias in this study could be nonresponse bias, which occurs when certain groups of individuals are more or less likely to respond to the survey. For example, if households with higher incomes are more likely to respond to the survey, the sample could be biased toward higher incomes and produce an overestimate of the population mean. On the other hand, if households with lower incomes are more likely to respond, the sample could be biased toward lower incomes and produce an underestimate of the population mean.
Browse Study Guides By Unit
👆Unit 1 – Exploring One-Variable Data
✌️Unit 2 – Exploring Two-Variable Data
🔎Unit 3 – Collecting Data
🎲Unit 4 – Probability, Random Variables, & Probability Distributions
📊Unit 5 – Sampling Distributions
⚖️Unit 6 – Proportions
😼Unit 7 – Means
✳️Unit 8 – Chi-Squares
📈Unit 9 – Slopes
✏️Frequently Asked Questions
📚Study Tools
🤔Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.