7.5 Carrying Out a Test for a Population Mean
5 min read•june 18, 2024
Jed Quiaoit
Josh Argo
AP Statistics 📊
265 resourcesSee Units
Calculating T-Scores
The first step in actually performing any statistical significance test is to calculate the test statistic used for that particular test. Since we are carrying out a significance test for a population mean, we should calculate a t-score. 💯
The t-score is a test statistic that is used in a t-test to evaluate the significance of the difference between the sample mean and a hypothesized population mean.
The t-score is calculated by dividing the difference between the sample mean and the hypothesized mean by the standard error of the mean. (The standard error of the mean is a measure of the variability of the sample mean and is calculated by dividing the standard deviation of the sample by the square root of the sample size.)
The larger the t-score, the more significant the difference between the sample mean and the hypothesized mean is.
When calculating a t-score, we use the general formula for critical values:
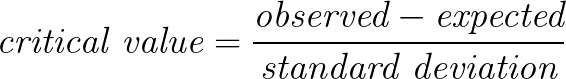
When we specify this formula for a t-score, we get the following:
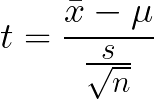
Where x̄ is our sample mean, 𝞵 is our hypothesized sample mean, s is our standard deviation of our sample and n is our sample size.
Example
Ricardo has a bag of 30 🍊s. The bag says that each orange weighs an average of 4.5 oz.
Ricardo weighs all of the oranges in his bag and finds that they have an average of 4.65 oz with a standard deviation of 0.8 oz.
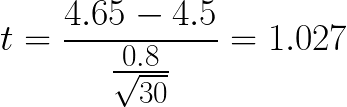
Calculating P-Value
When performing a hypothesis test, we could be performing either a one-tailed or two-tailed test. This depends on our alternate hypothesis when setting up our test. 🦊
The type of hypothesis test (one-tailed or two-tailed) is determined by the alternative hypothesis that you specify. If the alternative hypothesis is directional (e.g. "the population mean is greater than X"), then you would perform a one-tailed test because you're looking for a t-score only in one tail of our curve.
On the other hand, if the alternative hypothesis is non-directional (e.g. "the population mean is not equal to X"), then you would perform a two-tailed test since we are looking to find a t-score in either tail of our curve.
It's important to note that the choice of one-tailed or two-tailed test can have a significant impact on the results of the hypothesis test. A one-tailed test is more powerful than a two-tailed test because it allows you to detect a difference in a specific direction (e.g. the population mean is greater than X). However, this increased power comes at the cost of increased risk of a type I error (rejecting the null hypothesis when it is true). A two-tailed test is less powerful than a one-tailed test, but it reduces the risk of a type I error because it is not biased towards any particular direction. ✊
Back to the hypothesis test, we'll then need to reference our t-score chart to calculate our p value.
First, let's determine the degrees of freedom, which is always one less than our sample size.
Then, we find our t-score in the column matching our given degrees of freedom (df) to estimate our p-value. If the degrees of freedom can not be found in the chart, round down to the nearest df.
Example
In our example above with Ricardo's 🍊s, our df = 29. So we need to locate 29 df on the chart and then try to find 1.027.
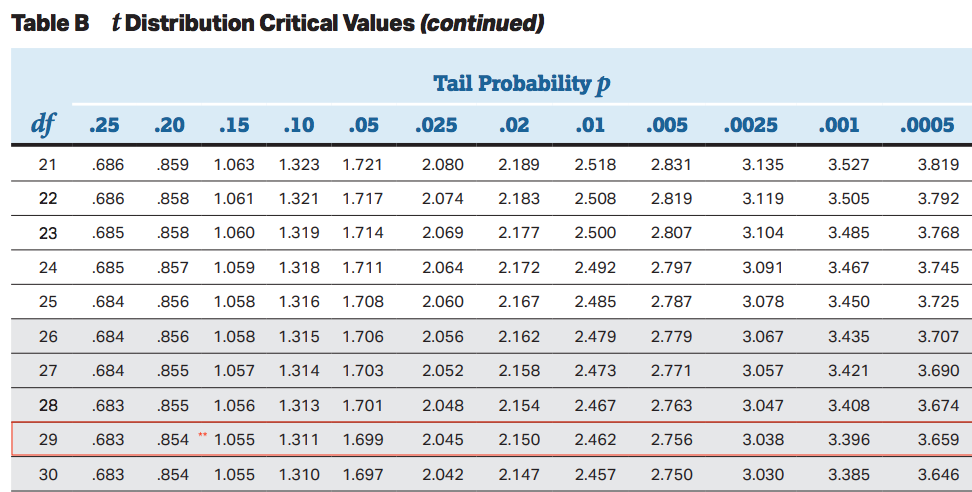
We can see in the t table, that the tail probability with df=29 and t-score of 1.027 is approximately 0.15 (since its close to 1.055).
- If we are doing a one tailed test, this is our p-value.
- If we are doing a two tailed test, we would double this to get 0.3 for our p-value (since the t curve is symmetric and tail probabilities are equal).
Using Calculator to Calculate T-Score and P-Value
Perhaps a much easier way to perform a one sample t test would be to use technology such as a graphing calculator. The most commonly used calculator for AP Statistics is the Texas Instruments TI-84. 📱
When performing a one sample t test, you will first enter into the stats menu:

Then, you will navigate over to tests and select option 2:

You are then given two options: you can enter the given sample statistics or let the calculator use data points entered in Lists to calculate your necessary test statistic and p value. We will proceed with our example using Ricardo's 🍊s.

Once you press calculate, it gives you your test statistic and p value. Both of these things are essential to list out in your written response to receive full credit on the AP exam. Also, it is important for a t-test for population mean to include your degrees of freedom, even though it is not listed in the computer output for the test.

Using P-Value to Make Conclusions
Once you have calculated the test statistic and p-value for your hypothesis test, you can use them to draw conclusions about the data. After all, the p-value is a measure of the likelihood of obtaining the observed results (or more extreme results) under the assumption that the null hypothesis is true. 🍀
If the p-value is less than the predetermined level of significance (usually 0.05), it means that the observed results are unlikely to have occurred by chance alone, and you can reject the null hypothesis in favor of the alternative hypothesis. On the other hand, if the p-value is greater than the level of significance, it means that the observed results are not statistically significant and you cannot reject the null hypothesis.
Templates
- p < 𝞪: "Since p < 𝞪, we reject our Ho. We have convincing evidence at the 𝞪 level that (Ha in context of problem)."
- p > 𝞪: "Since p > 𝞪, we fail reject our Ho. We do not have convincing evidence at the 𝞪 level that (Ha in context of problem)."
As always, we NEVER "accept" a null or alternate hypothesis. 🙅
🎥 Watch: AP Stats - Inference: Hypothesis Tests for Means
Browse Study Guides By Unit
👆Unit 1 – Exploring One-Variable Data
✌️Unit 2 – Exploring Two-Variable Data
🔎Unit 3 – Collecting Data
🎲Unit 4 – Probability, Random Variables, & Probability Distributions
📊Unit 5 – Sampling Distributions
⚖️Unit 6 – Proportions
😼Unit 7 – Means
✳️Unit 8 – Chi-Squares
📈Unit 9 – Slopes
✏️Frequently Asked Questions
📚Study Tools
🤔Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.