Jed Quiaoit
L
Lusine Ghazaryan
AP Statistics 📊
265 resourcesSee Units
Intro to Z-Scores
This section introduces you to z-scores. When I think of statistics, one of the first things that come in my mind is standard deviation and z-scores. So, what exactly are z-scores? A z-score, also known as a standard score, is a measure of how many standard deviations a data point is from the mean (not median) of a data set. It is calculated by subtracting the mean of the data set from the value of the data point, and then dividing the result by the standard deviation of the data set. The formula is simple but very powerful. It is resistant to units, and it can be used to compare any activity. 🏃
FORMULA: z = (x - x̄) / s
where z = z-score, x = a data point, x̄ = mean value, s = standard deviation
For example, consider a data set with a mean of 50 and a standard deviation of 10. If a data point has a value of 70, the z-score for that data point would be calculated as follows:
z-score = (70 - 50) / 10 = 2
This z-score of 2 means that the data point is 2 standard deviations above the mean of the data set.
z-scores are useful for comparing values within a data set and for determining whether a value is unusual or extreme relative to the rest of the data. They can also be used to standardize data for comparison between different data sets.
For this reason, z-scores are also called standardized values. In sports, when the judges have to calculate the final score for athletes, they use z-scores.
Negative z-scores mean that the data value is below the mean, while positive z-scores mean that the data value is higher than the mean. The further the value is from the mean, irrespective of the sign, the more unusual the value is. Here is the formula for z-score:
As you see, when we are standardizing data into z-scores, we are shifting them by the mean and rescaling by the standard deviation.
Wait, but how does standardization affect the distribution? 🤔
In general, shifting data changes the distribution but leaves the shape and spread unchanged. The center shifts with other measures of the position such as percentiles, mininum, and maximum by the same amount of value.
What about rescaling? You may guess already that with rescaling data when we multiply or divide any number to a data set, the shape of distribution won’t change (it will just look stretched or squeezed), but everything else will change, the mean, minimum, maximum, range, IQR, and standard deviation. AP Statistics MCQs always will ask questions like this to trick you if you know how the shifting and rescaling affect the shape, center, and spread, so get ready to encounter such questions! 😉
Normal Model: More than Just a Hump
You may have learned about "normal" models or bell-shaped curves in your Algebra class and through calculus. Some sets of data may be described as approximately normally distributed. A normal curve is mound-shaped and symmetric. 🐫
Normal models are appropriate for symmetric and unimodal distributions. The normal model has two parameters (the population mean, µ, and the population standard deviation, σ) and is often written as N(mean, sd). These parameters do not come from data but are part of the model.
You might be curious: what variables in daily life can a normal distribution model. The answer? A lot! Here's a list of a small sample (get it?) of all the variables out there that follow a normal distribution: 👶
- Height
- IQ scores
- Blood pressure
- Birth weight
- Body temperature
- Life expectancy
- Income
Standard Normal Model
The standard normal model has a symmetrical bell-shaped curve, with the mean at 0 and the standard deviation at 1. Z-scores are actually based on the standard normal model. When working with data that is normally distributed, it is often helpful to standardize the data by converting the values to z-scores, which allows for easier comparison and analysis. This standard model can be written as N(0,1), and to standardize, we need to subtract from mean and rescale by the standard deviation.
z = (x - x̄) / s
The standard normal model, as well as other normal distributions, are based on the assumption that the data follows a symmetrical, bell-shaped curve. In order for the standard normal model or other normal distributions to be a good model for the data, the data must be approximately symmetric and unimodal.
If the data is not symmetric or is multimodal (i.e. has multiple peaks), then the standard normal model or other normal distributions may not be a good fit for the data. In such cases, it may be necessary to use a different statistical model or transform the data in some way to make it more suitable for analysis.
To check whether the data is approximately symmetric and unimodal, it is common to look at the histogram of the data or create a normal probability plot. A histogram should show a roughly symmetrical distribution, with a single peak in the middle. Don’t model data with a Normal model without checking the "Nearly Normal" Condition. ✔️
The Empirical (68–95–99.7) Rule
Often we ask ourselves whether we are normal or not. If we are normal, then we should be doing about the same things as the average people do. The 68-95-99.7 rule (Empirical Rule) tells us that if we all behave normally then about 68% of the values fall within one standard deviation of the mean, about 95% of the values fall within two standard deviations of the mean, and about 99.7%—almost all—of the values fall within three standard deviations of the mean. 🙌
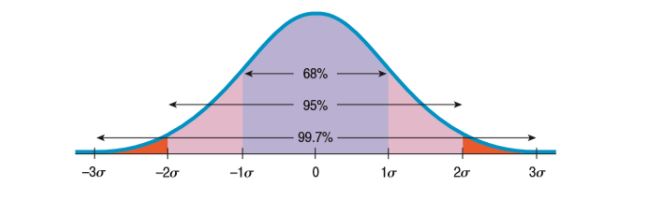
Source: The College Board
⭐ The EMPIRICAL RULE: "For a normal distribution, approximately 68% of the observations are within 1 standard deviation of the mean, approximately 95% of observations are within 2 standard deviations of the mean, and approximately 99.7% of observations are within 3 standard deviations of the mean."
This rule works fine in normal models, but do not ever try it for skewed distributions as it will fail. For skewed distributions, we can use Chebisheeve’s (a Russian mathematician) rule, but that’s beyond the AP Statistics course. When sketching the normal model, start with the center and extend the tails to the sides, but you do not need to go beyond three standard deviations as there is very little left beyond it, and also don’t touch the line because it extends forever. The place where the bell shape starts to curve downward is called the inflection point, which is exactly one standard deviation away from the mean.
🎥 Watch: AP Stats - Normal Distributions
🎥 Watch: AP Stats - Normal Curve and Normal Calculations
Key Vocabulary
- Density Curve
- Normal Distribution
- The Empirical Rule
- Normal Probability Plot
Practice Problems
(1) A sample of 50 students at a school took a math test, and the mean score was 75 out of 100. The standard deviation of the scores was 10.
A. Calculate the z-score for a student who scored a 90 on the test.
B. Interpret the z-score. What does this mean in the context of statistics and test scores?
(2) A baseball player has a batting average of 0.300, which is the mean number of hits per at-bat over the course of a season. The standard deviation of the player's batting average is 0.050. In a recent game, the player had 4 at-bats and scored 3 hits. Calculate the z-score for the player's performance in this game.
(3) Another big idea within Unit 1 of the AP Stats course is the idea that percentiles and z-scores may be used to compare relative positions of points within a data set or between data sets.
A study was conducted to determine the average number of hours per week that college students spend studying. The study found that the average number of hours per week spent studying is 15 hours, with a standard deviation of 4 hours. A random sample of 25 college students was selected and the number of hours they spent studying per week was recorded. The sample mean was found to be 13 hours per week, with a z-score of -1.5.
Based on the information provided, what is the average number of hours per week that college students spend studying?
Answers
(1) A. First, we subtract the mean score from the student's score to find the difference:
90 - 75 = 15
Next, we divide the difference by the standard deviation of the scores:
15 / 10 = 1.5
B. The z-score for the student's score is 1.5, which means that the student scored 1.5 standard deviations above the mean test score.
Note: When calculating z-scores, it is important to use the same units for the mean, standard deviation, and data point being analyzed. In this example, all values are in units of points on the test. If the mean and standard deviation were in different units (e.g. percent instead of points), it would be necessary to convert the values to the same units before calculating the z-score.
(2) First, we calculate the player's batting average for the game by dividing the number of hits by the number of at-bats:
batting average = 3 / 4 = 0.750
Next, we subtract the mean batting average from the game batting average to find the difference:
0.750 - 0.300 = 0.450
Finally, we divide the difference by the standard deviation of the player's batting average:
0.450 / 0.050 = 9
The z-score for the player's performance in this game is 9, which means that the player's performance was 9 standard deviations above the mean. This indicates that the player had a very strong performance in this game!
(3) To solve this problem, we can use the formula for calculating a z-score:
z = (x - x̄) / standard deviation
In this case, the mean is 15 hours per week and the standard deviation is 4 hours per week. The value we are trying to find, the average number of hours per week that college students spend studying, is represented by x.
Substituting these values into the formula, we get:
z = (x - 15) / 4
We are given that the z-score is -1.5, so substituting this value into the formula gives us:
-1.5 = (x - 15) / 4
Multiplying both sides of the equation by 4 gives us:
-6 = x - 15
Adding 15 to both sides of the equation gives us:
x = 9
Therefore, the average number of hours per week that college students spend studying is 9 hours! Does that sound reasonable in your experience? Hmm...
Browse Study Guides By Unit
👆Unit 1 – Exploring One-Variable Data
✌️Unit 2 – Exploring Two-Variable Data
🔎Unit 3 – Collecting Data
🎲Unit 4 – Probability, Random Variables, & Probability Distributions
📊Unit 5 – Sampling Distributions
⚖️Unit 6 – Proportions
😼Unit 7 – Means
✳️Unit 8 – Chi-Squares
📈Unit 9 – Slopes
✏️Frequently Asked Questions
📚Study Tools
🤔Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.